Intro to Deep Learning by fast.ai
fast.ai 2020 course lesson 1 notes


- What you don't need, to deep learning
- Where is deep learning the best known approach?
- Neural Networks: A Brief History
- The fast.ai Learning Philosophy
- The Software: PyTorch, fastai, and Jupyter
- What Is Machine Learning?
- How Our Image Recognizer Works
- Jargon Recap
- Use Judgment in Defining Test Sets
- Before the Next Lesson
What you don't need, to deep learning
| Myth(don't need) | Truth |
|---|---|
| Lots of math | Just high school math is sufficient |
| Lots of data | We've seen record-breaking results with <50 items of data |
| Lots of expensive computers | You can get what you need for state of the art work for free |
A lot of world class research projects have come out of the fastai students based on a single GPU, using small data or without a traditional background.

Neural Networks: A Brief History
The Start
In 1943, Warren McCulloch and Walter Pitts developed a mathematical model of an artificial neuron.
In 1957, Frank Rosenblatt built the first device that actually used these principles, the Mark I Perceptron at Cornell.
We are now about to witness the birth of such a machine–-a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control.
---- Frank Rosenblatt
The First AI Winter
1969, Marvin Minsky adn Seymour Papert wrote a book called Perceptrons and pointed out that a single layer of a NN cannot learn some simple but critical functions (such as XOR) and using multiple layers of the devices would allow these limitations to be addressed. Unfortunately, only the first of these insights was widely recognized.
The Second Winter
In theory, adding just one extra layer of neurons was enough to allow any mathematical function to be approximated with these neural networks, but in practice such networks were often too big and too slow to be useful. Although researchers showed 30 years ago that to get practical good performance you need to use even more layers of neurons, it is only in the last decade that this principle has been more widely appreciated and applied.

Projects and Mindset
It helps to focus on your hobbies and passions–-setting yourself four or five little projects rather than striving to solve a big, grand problem tends to work better when you're getting started.
Questionnaire
After every chapter there are questionnaire instead of a summory of keynotes. It doesn't matter how many you get right but it just confirms that you haven't missed anything important. If you don't understand something after some time just continue and come back after a few chapters.
The Software: PyTorch, fastai, and Jupyter
fastai is built top of PyTorch and these are written in Python and it's the language we will use during this course. Many people think that fastai is just for beginners and teachers but it's actually using layered API which makes it infinite customizable and practical for every purpose.
Jupyter Notebook is coding environment often used by DL people. It's easier to experiment things using Jupyter Notebooks than running Python code in terminal. Linux highly recommended.
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
Above code classifies cat and dog images. This is a deep learning model. Notice that this happened in less than 2 minute.
What Is Machine Learning?
The training of programs developed by allowing a computer to learn from its experience, rather than through manually coding the individual steps.
In 1949, an IBM researcher named Arthur Samuel started working on machine learning.
By 1961 his checkers-playing program beat the Connecticut state champion.
In his classic 1962 essay "Artificial Intelligence: A Frontier of Automation", he wrote:
Suppose we arrange for some automatic means of testing the effectiveness of any current weight assignment in terms of actual performance and provide a mechanism for altering the weight assignment so as to maximize the performance.
We need not go into the details of such a procedure to see that it could be made entirely automatic and to see that a machine so programmed would "learn" from its experience.
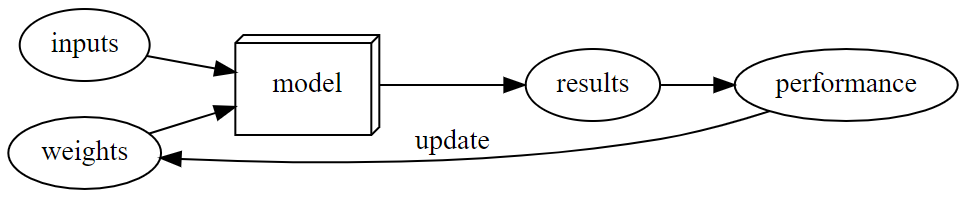
using a model after it's trained looks like: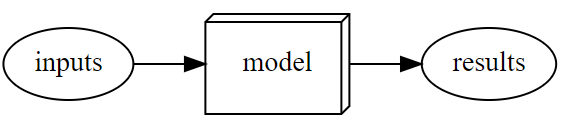
Limitations Inherent To Machine Learning
- A model cannot be created without data.
- A model can only learn to operate on the patterns seen in the input data used to train it.
- This learning approach only creates predictions, not recommended actions.
- It's not enough to just have examples of input data; we need labels for that data too
Neural Network
- Universal approximation theorem shows that Neural Network can solve any problem to any level of accuracy, in theory.
- In practice, they are often a suitable kind of model, and you can focus your effort on the process of training them—that is, of finding good weight assignments.
Stochastic Gradient Descent (SGD)
- One could imagine that you might need to find a new "mechanism" for automatically updating weights for every problem.
- a completely general way to update the weights of a neural network, to make it improve at any given task.
- the effectiveness of ... → loss
- weight assignment → parameters of Neural Networks
- performance → predictions
- mechanism for ... → stochastic gradient descent (SGD)
- maximize the performance → Minimize the Loss
How Our Image Recognizer Works
from fastai2.vision.all import *
Normally people import only parts they need but this method imports everything. fastai library is designed in a way that this only gives you the parts you need.
path = untar_data(URLs.PETS)/'images'
This downloads the dataset to computer if not exists.
def is_cat(x): return x[0].isupper()
This checks if the first character is uppercase because this is how cats are labeled.
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
This creates "data loader":
- from_name_func: labels can be extracted using a function applied to the filename
- valid_pct=0.2: randomly hold out 20% of the data as validation set; the remaining 80% is called the training set
- seed=42: sets the random seed to make sure any differences are due to the changes to the model
- item_tfms=Resize(224): each item is resized to a 224-pixel square
Why 224 pixels? This is the standard size for historical reasons (old pretrained models require this size exactly), but you can pass pretty much anything. If you increase the size, you'll often get a model with better results (since it will be able to focus on more details), but at the price of speed and memory consumption; the opposite is true if you decrease the size.
learn = cnn_learner(dls, resnet34, metrics=error_rate)
Learner is the thing that learns.
- It gets the data loader, architecture (in this case resnet34), and the metric human uses to evaluate it.
- cnn_learner also has a parameter pretrained, which defaults to True.
Using pretrained models is the most important method we have to allow us to train more accurate models, more quickly, with less data, and less time and money.
The 34 in resnet34 refers to the number of layers in this variant of the architecture (other options are 18, 50, 101, and 152). Models using architectures with more layers take longer to train, and are more prone to overfitting (i.e. you can't train them for as many epochs before the accuracy on the validation set starts getting worse). On the other hand, when using more data, they can be quite a bit more accurate.
learn.fine_tune(1)
- Use one epoch to fit just those parts of the model necessary to get the new random head to work correctly with your dataset.
- Use the number of epochs requested when calling the method to fit the entire model, updating the weights of the later layers (especially the head) faster than the earlier layers (which, as we'll see, generally don't require many changes from the pretrained weights).
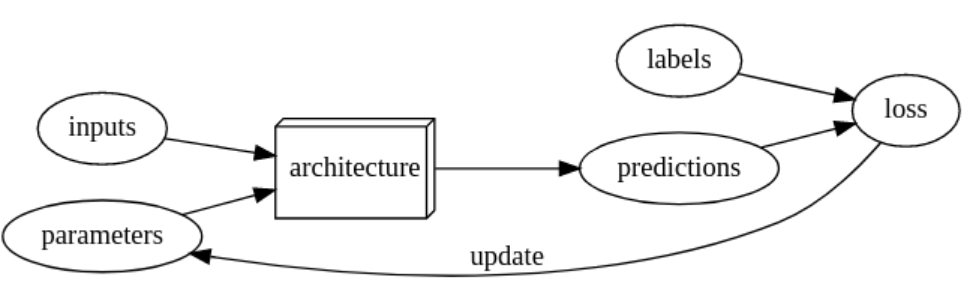
Jargon Recap
| Term | Meaning |
|---|---|
| Label | The data that we're trying to predict, such as "dog" or "cat" |
| Architecture | The template of the model that we're trying to fit; the actual mathematical function that we're passing the input data and parameters to |
| Model | The combination of the architecture with a particular set of parameters |
| Parameters | The values in the model that change what task it can do, and are updated through model training |
| Fit | Update the parameters of the model such that the predictions of the model using the input data match the target labels |
| Train | A synonym for fit |
| Pretrained model | A model that has already been trained, generally using a large dataset, and will be fine-tuned |
| Fine-tune | Update a pretrained model for a different task |
| Transfer learning | Using a pretrained model for a task different to what it was originally trained for |
| Epoch | One complete pass through the input data |
| Loss | A measure of how good the model is, chosen to drive training via SGD |
| Metric | A measurement of how good the model is, using the validation set, chosen for human consumption |
| Validation set | A set of data held out from training, used only for measuring how good the model is |
| Training set | The data used for fitting the model; does not include any data from the validation set |
| Overfitting | Training a model in such a way that it remembers specific features of the input data, rather than generalizing well to data not seen during training |
| CNN | Convolutional neural network; a type of neural network that works particularly well for computer vision tasks |
Classification vs Regression
- A classification model is one which attempts to predict a class, or category
- A regression model is one which attempts to predict one or more numeric quantities, such as a temperature or a location.
Metric vs Loss
- Loss: a "measure of performance" easy for stochastic gradient descent to use
- metric: easy for you to understand and close to what you want the model to do
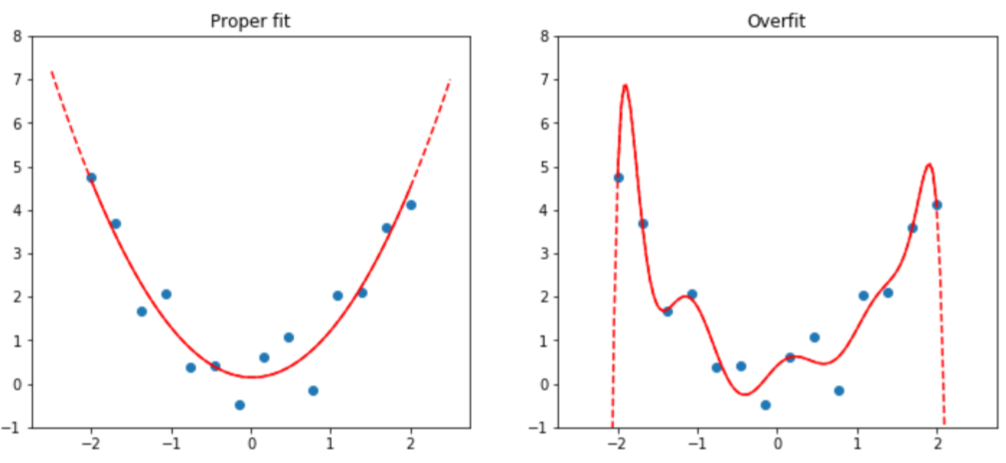
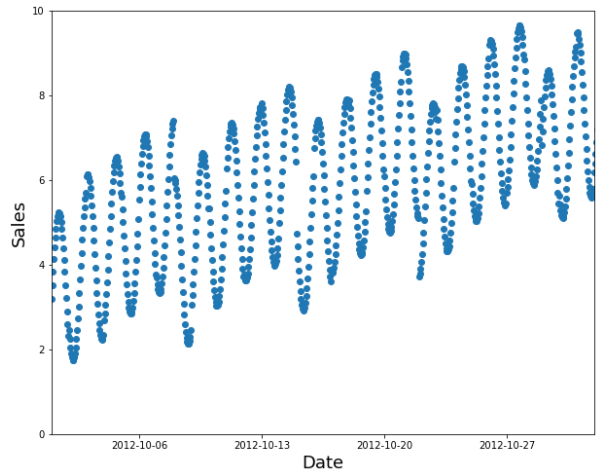
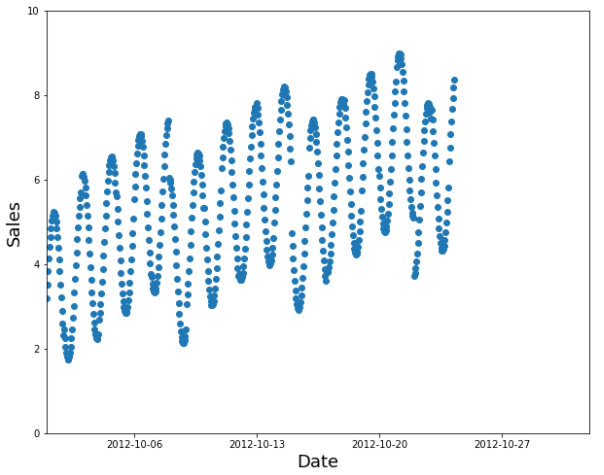
A random subset is a poor choice
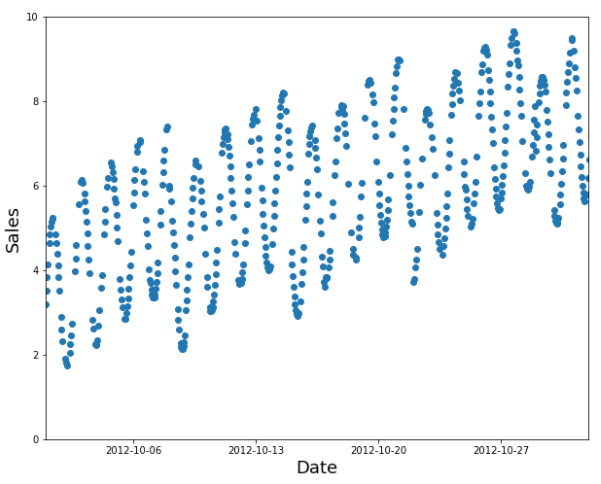
Instead, use the earlier data as your training set (and the later data for the validation set).
In the Kaggle distracted driver competition, the independent variables are pictures of drivers at the wheel of a car, and the dependent variables are categories such as texting, eating, or safely looking ahead.
 If you put one of the images in your training set and one in the validation set, your model will have an easy time making a prediction for the one in the validation set, so it will seem to be performing better than it would on new people. Another perspective is that if you used all the people in training your model, your model might be overfitting to particularities of those specific people, and not just learning the states (texting, eating, etc.).
If you put one of the images in your training set and one in the validation set, your model will have an easy time making a prediction for the one in the validation set, so it will seem to be performing better than it would on new people. Another perspective is that if you used all the people in training your model, your model might be overfitting to particularities of those specific people, and not just learning the states (texting, eating, etc.).